
If you’ve ever spent hours manually digging through websites just to pull a few lines of data, you know just how draining and inefficient that entire process can be. It’s not only mind-numbing and repetitive but also the worst possible use of your time if you’re working in sales or marketing.
And as operations scale, this problem only grows further.
The more prospects you need, the more tabs you open, the more spreadsheets you build — until you realize you’re spending entire workdays on manual data scraping instead of doing actual business.
The good news is that, with the right setup, this tedious process can now run quietly in the background, pulling web data that a manual search couldn’t uncover, and providing teams with clean, fully enriched data lists.
This is where automated web scraping comes into play.
Clay, which is the leading software in this domain, is a no-code data automation platform that lets you extract, enrich, and sync business data from all across the web in minutes.
Let’s break down exactly how it works, why it matters, and how teams (and agencies like ColdIQ) are using Clay to turn raw website data into sales opportunities on autopilot.
What is web scraping?
Back in the day, getting relevant business data meant either spending hours on research or hiring developers to write and maintain custom Python scripts. Neither of these options was scalable or accessible to most firms.
With data scraping tools, however, every business out there can automatically extract information from websites and structure it into actionable data. In simple terms, it’s like teaching software to do the entire manual researching, copy-pasting, and organization process for you, only faster and more accurately.
Nowadays, data is the main fuel for virtually all business decisions across all industries, which is why businesses scrape data for all sorts of reasons, from building sales prospect lists to tracking competitors and beyond.
With the no-code Clay scraping tool, the entire process is effortless — you simply point, click, and the data gets scraped for you. No scripts, no setup hell, no wasted time.
Source: Clay Chrome extension
How does web scraping work?
Before diving into how to set up your Clay scraping workflow, it’s good to understand the basics. At its core, web scraping follows a very simple logic loop:
- You visit a webpage.
- You identify the elements you want (like names, emails, prices, company info, etc.).
- Software extracts those elements from the site’s code (HTML).
- Everything is exported into a structured format, ready to integrate with business tools.
The great thing about modern scrapers is that they add another, fifth layer: automation.
You can upload and scrape entire lists of URLs at once, auto-detect fields, extract info inaccessible to manual search, clean and verify the data, and even delegate AI to go find the data you need without providing the web sources yourself (more on that shortly).
The next logical question is how to scrape website data into Excel or Google Sheets to filter, sort, or quickly find team members, as well as having a centralized database available to the entire team.
Web scrapers make it very simple — you simply download the CSV file and upload it to Excel.
Tools like Clay also offer all those data formatting features and beyond directly within the platform. For example, you could set conditions like “only include companies with more than 50 employees” before exporting a single line.
Other useful tools worth knowing (quick hits):
- Jina — a search-AI stack that turns messy web pages into clean, structured text (Markdown/JSON) and adds search/ranking so you can quickly find and organize what matters. Use it when you need reliable page content before downstream enrichment.
- Firecrawl — a developer API that crawls a site (even JS-heavy ones), follows links, and gives you a cleaned copy of the pages. Useful when you want a “grab the whole site” endpoint you can feed into an LLM or a database, rather than a point-and-click tool.
- Instant Data Scraper — a free Chrome extension for quick one-off pulls that auto-detects tables/lists and exports straight to CSV or Excel. Great for fast, low-volume, and non-technical extractions.
For one-off grabs, free lightweight tools like these are very handy, but when you want repeatable and scalable lists with automated data extraction and enrichment, Clay is the one to carry your workflow the rest of the way.
What are the benefits of web scraping?
Automated web scraping is about much more than just saving a few clicks. It brings teams speed, accuracy, and scale in their data-gathering workflows, which ultimately affect all other processes and decisions, and therefore having a direct impact on revenue:
1. Time and cost efficiency
Even the best SDRs waste hours each week researching and structuring data, all while potentially valuable deals sit untouched. With automated web scraping, those hours turn into seconds, allowing teams to focus on outreach, calls, and strategy. As Kris Rudeegrap, CEO of Sendoso, said:
“Automating mundane tasks with Clay allows revenue teams to focus on high intent, best fit accounts and prioritized selling, optimizing the limited hours available each day for more critical and impactful activities,”
2. Smarter decision-making
The best decisions are data-driven, and web scraping gives teams fresh, structured, and real-time information to make better and smarter decisions, especially for those that impact the entire business.
3. Scalability
Manual research doesn’t scale, simple as that. But with automated web scraping, whether you want to pull 100 or 10,000 company profiles, it’s the same effort. Once a custom scraping blueprint is created, sky is the limit in terms of volume.
4. Automation and integration
A less talked-about perk of web scraping is that the entire process can be connected to other software. Whether it’s enriching sourced data with intent signals or pushing it into an outreach sequence with lemlist, Clay data scraping seamlessly integrates into your existing ecosystem.
“With Clay, we’ve reimagined how outbound sales works. We’re leaner, faster, and more precise — and we’re seeing a higher level of engagement.” — JJ Tang, CEO & Co-founder, Rootly.
5. Versatility across use cases
Web scraping is valuable for virtually all business processes, be it for lead generation or looking for potential job candidates. For instance, if LinkedIn is part of your motion, LinkedIn event extraction and LinkedIn group extraction help you pull attendee/member lists into Clay, then enrich and segment them for further outreach or analysis.
Web scraping use case examples
Speaking of the versatility of automated web scrapers, while they can bring tremendous value to businesses across all workflows, let’s zoom in on the three specific use cases that usually bring the greatest ROI:
- Sales and lead generation → scrape company websites and LinkedIn profiles to identify decision-makers in targeted companies, then enrich their profiles with verified emails and relevant company data like headcount, budget, and software used. Once enriched, those leads can be pushed straight into your outreach platform with a click.
- Market research → scrape pricing pages, job postings, product catalogs, or press sections to spot emerging trends, marketing intelligence, and competitor shifts before they even make the announcements. Web scraping keeps you on top of any industry/competition changes in real time, without the need for manual monitoring.
- Competitor analysis → scrape competitors' pricing, client, or partner pages to uncover who they're working with, whether they’re expanding, and more. You can also uncover press releases, hiring signals, or new funding rounds to see which industries or regions they’re doubling down on.
At the end of the day, web scrapers give you the data intelligence you need to optimize processes and make informed decisions, rather than relying on guesswork or any trial-and-error methods.
What is the Clay scraper?
Clay Scraper is the no-code Chrome Extension engine that powers Clay’s data extraction. It lets you pull information from any website in seconds — visually, without writing a single line of code.
You can capture everything from team names and pricing tiers to job listings and contact details, then enrich that data with over 50 attributes inside the same workspace — things like funding, tech stack, location, LinkedIn profiles, and so on.
But Clay Scraper is just one part of a much larger system. Clay itself is a full data automation platform built for B2B teams, combining scraping, enrichment, AI research, and workflow automation all under one roof.
So instead of juggling five different tools to find, clean, and sync data, you can do it all inside Clay. That’s why teams and agencies like ColdIQ use it daily to build complete, code-free data pipelines that feed straight into their outbound and growth operations.
So if your goal is lead generation, B2B sales, or research, Clay isn’t just the easiest way to scrape data — it’s by far the smartest way to turn that data into a functional pipeline.
How does Clay web scraping work?
Clay web scraping is surprisingly simple. Even if you’ve never touched a line of code, you can build a full data collection workflow in minutes. The setup is visual, quick, and built to scale, without the headaches of coding.
Here’s how Clay data scraping works in real life:
- Install the Clay Chrome extension
Log in to your Clay workspace, open any site, and click the Clay icon in your toolbar. The extension connects straight to your Clay tables, so whatever you scrape ends up right where it should — inside your workspace, ready to use.
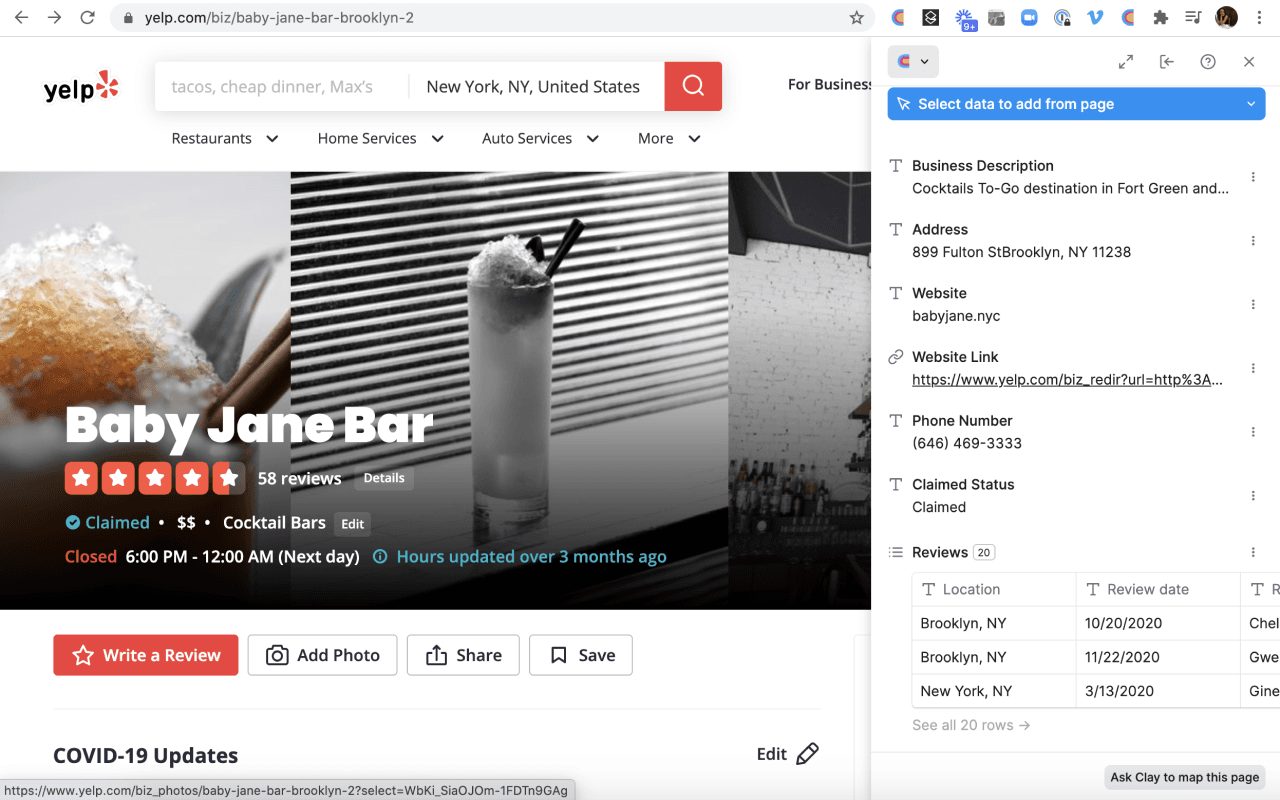
- Select the data you want
The extension tries to auto-detect patterns on the page, like lists of people, companies, or pricing. You can tweak it or highlight specific fields yourself: names, titles, emails, URLs, locations, basically anything you need. You get a live preview of what you’re about to capture before running the scrape.
Source: Clay Chrome extension
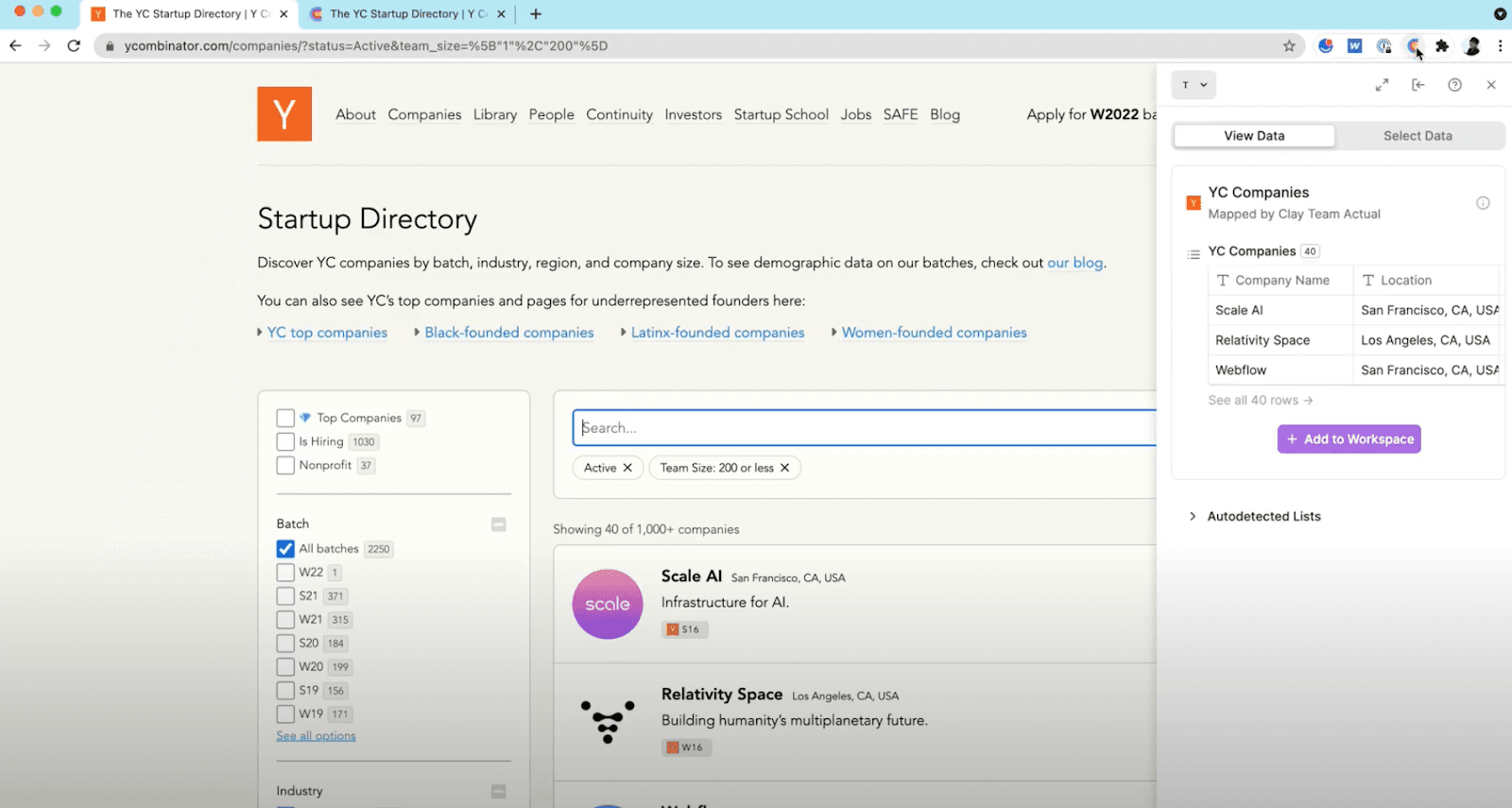
- Map the fields to your Clay table
Each element you pick gets linked to a column, for example: Name, Role, Company, Website, Email. You can preview the result and check if it looks right. Once confirmed, Clay structures it into clean, ready-to-use rows inside your table.
To avoid confusion: selection (step 2) = choosing the on-page elements, whereas mapping (step 3) = assigning those selections to columns in your table.
- Save it as a recipe
Recipes are basically reusable templates. Once you’ve set one up, you can run it again on similar pages — perfect for scraping team sections, job boards, or directories without rebuilding the setup every time.
- Run the scrape
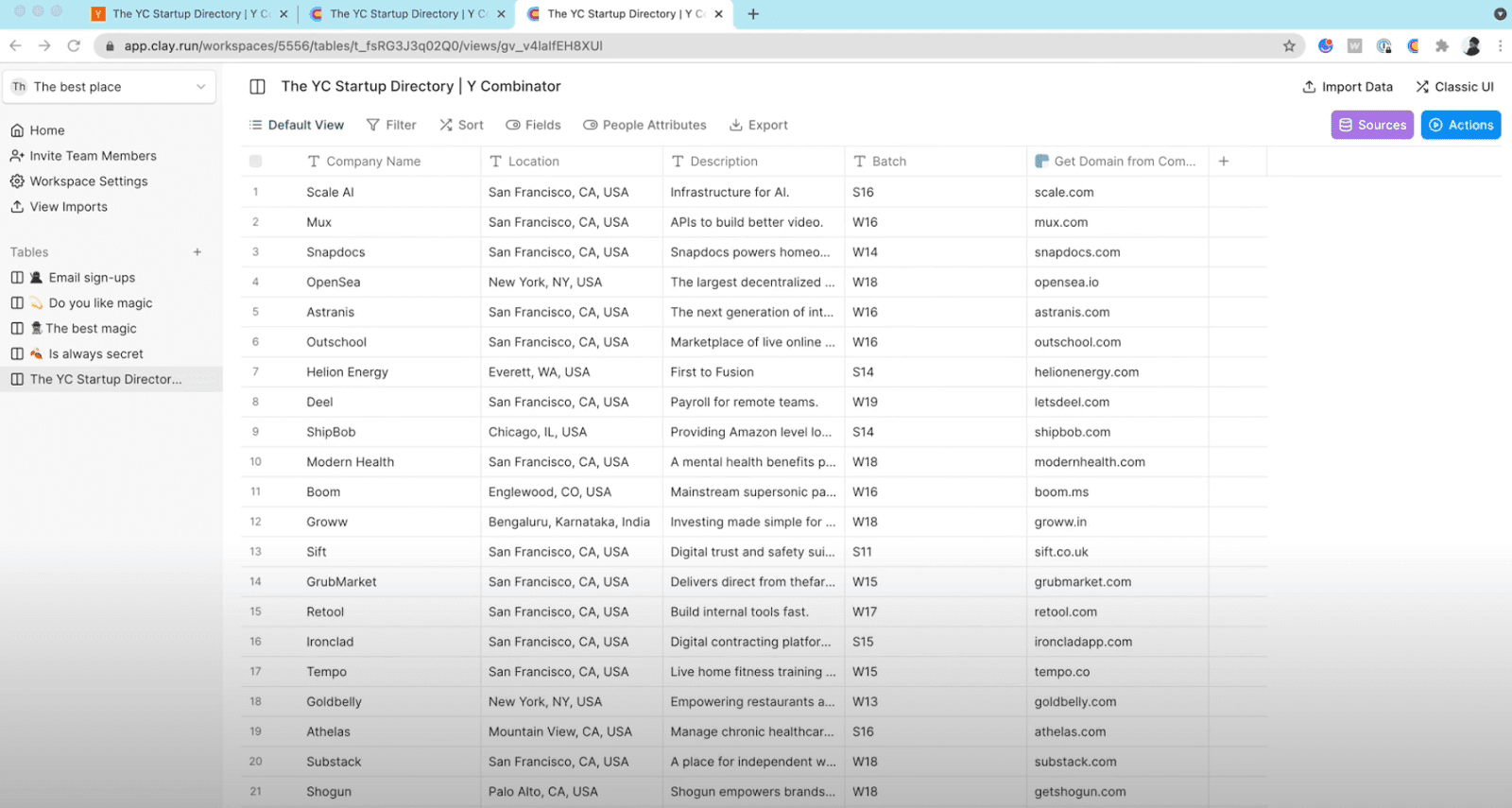
Hit Run, and Clay starts collecting and organizing the data automatically. From there, you can clean, filter, or enrich everything directly inside the app. If you’re scraping multiple domains, just upload a list of URLs, apply the same recipe, and Clay goes through them one by one while you focus on other work.
Because everything’s visual, the learning curve is practically zero. No CSS selectors, no XPath, no code. You just pick what you need, hit run, and it appears right in your table, clean and structured:
Source: Clay Chrome extension
And once you’re comfortable with that part, you can push it even further by pairing it with Claygent, their built-in AI agent that finds and extracts deeper insights from across the web automatically.
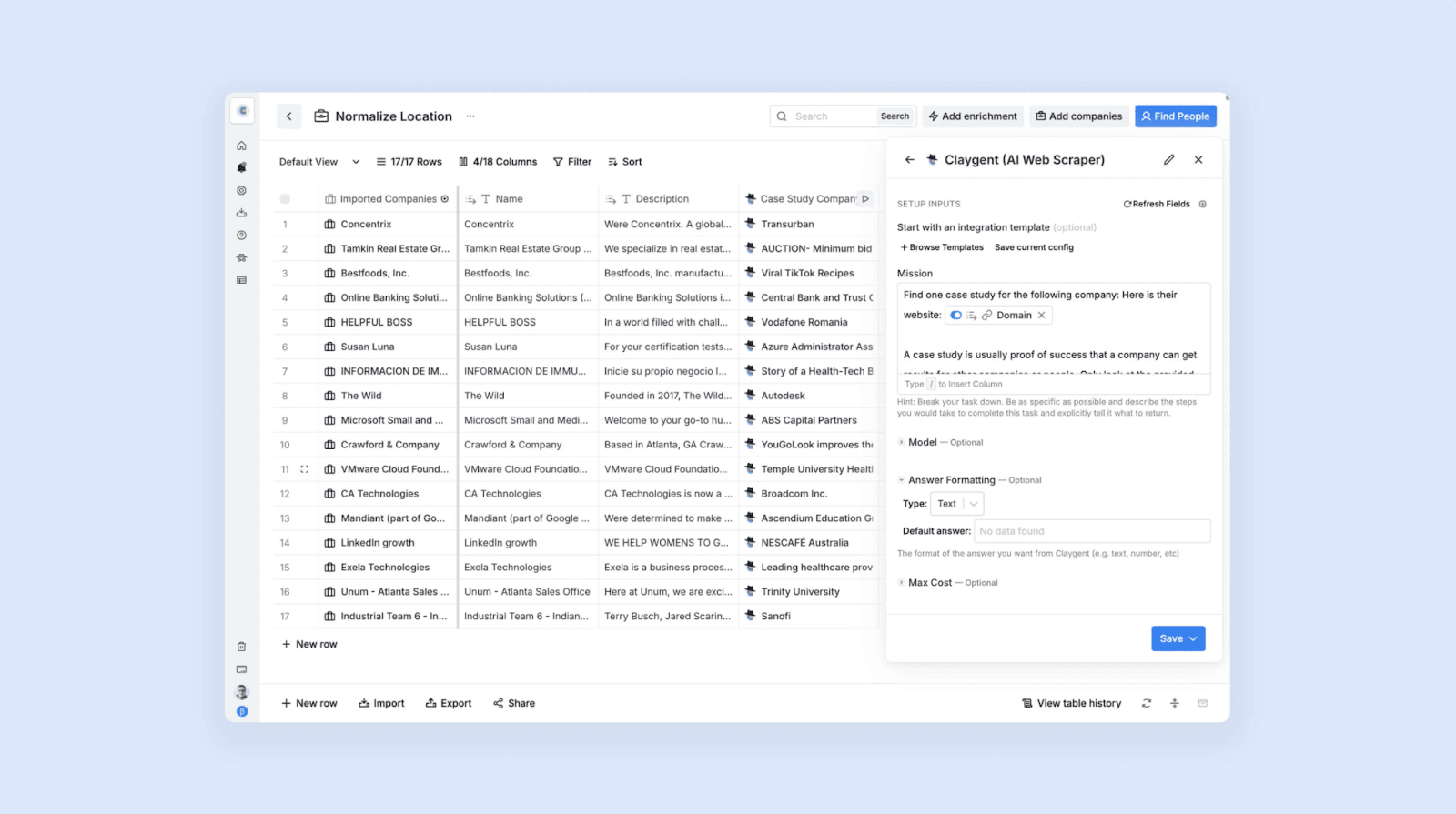
Claygent: AI web scraper
Claygent is Clay’s built-in AI agent — imagine ChatGPT but with the power to actually browse and extract live data relevant to your business and workflow.
Instead of clicking around or setting selectors, you can simply tell it what you want with a simple prompt in plain English.
Examples:
- “Find the pricing page URL for each company in this list.”
- “Check if this company is hiring for marketing roles.”
- “List three competitors mentioned on their website.”
Source: Clay
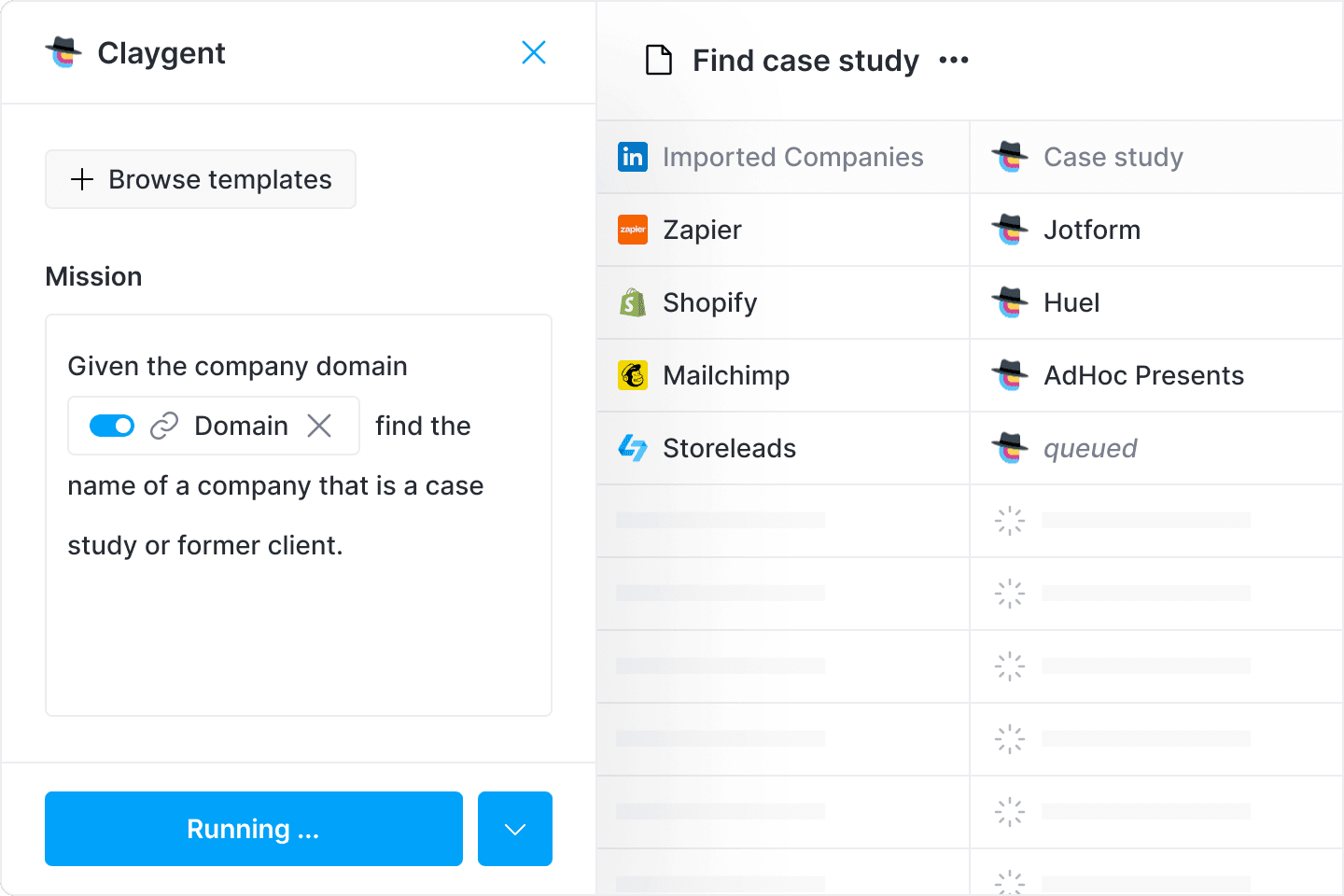
Claygent searches, scrapes, and automatically returns the results structured into your Clay table. It also reads unstructured pages (like blog posts or About pages) that normal scrapers usually can’t parse.
On top of that, you can:
- Create and version prompts in a simple builder, test them, and reuse the ones that produce the cleanest outputs.
- Use the Navigator feature to take human-like actions on tricky pages (apply filters, click buttons, even submit forms) so you can capture data that basic scrapers would miss.
- Run company- and people-level research in the same flow: first pulling company facts, then jumping straight into decision-maker context without leaving the table.
- Blend in first-party sources (e.g., CRM profiles or call transcripts) to enrich what Claygent finds on the open web when you need extra context.
This ultimately means that you can blend structured Clay data scraping with open-ended research in the same workflow. For example:
- Scrape company URLs with the Chrome extension.
- Use Claygent to answer “What does this company do?” or “Which tech stack are they using?”
- Enrich, score, and export, all within one table.
Source: OpenAI
AI-driven scrapers like Claygent aren’t perfect, and sometimes the data may need human review, but when paired with the structured, fact-checked, and verified Clay scraping, you get unbeatable coverage.
And since prompts can be saved and reused, you can replicate powerful AI-research routines across multiple projects.
How to automate Clay scraping on a schedule?
Scraping once or twice brings great results, but scheduling automated scraping is where the real value kicks in.
In Clay, you can run scrapes (and the follow-up steps) on a scheduled timer (daily, weekly, monthly, or at a specific hour), so your tables maintain fresh data without any supervision.
A simple setup looks like this:
- Pick the recipe you already use,
- Choose the cadence (e.g., every Tuesday at 08:00),
- Chain the next steps: enrichment → dedupe → push to CRM/outreach.
A real-life example could be: tracking companies hiring for “Head of Growth” and setting the scheduled run to “Weekdays at 08:00”. This way, new companies start landing in your table every day, where Clay will automatically enrich each company profile, filter duplicates, and structure all the data to your liking. Your team will now start their day with fresh leads (and additional context) sitting in their table.
B2B is a volatile industry, so data often decays fast — people switch roles, sites change, pages move. Scheduled runs keep your lists updated at all times with real-time data.
A few practical tips to scale this cleanly:
Process only new/changed rows
Add a Status column (e.g., “Synced” = Yes/No). Filter your scheduled run to Synced = No, and keep updating after each workflow.
Set soft guards
Choose a schedule that matches how often target sites change or update to avoid overly aggressive frequencies.
Set alerts via integrations
Have Slack or email ping you when a run fails or when row counts dip. You’ll need connected integrations or webhooks for this.
Validate changes
If a site layout changes, do a quick spot-check on your mapping/recipe before the next scheduled run.
Chain the workflow
In one scheduled run, use Clay integrations to scrape, enrich, score, then push to your CRM or outreach tool.
Log outcomes
Track results in the table by adding columns like “Last run”, “Rows added”, “Notes/Errors”, and fill them from the workflow for fast and consistent QA.
Set it correctly once, and Clay turns into a quiet researcher that automatically updates your pipeline at your desired schedule, without the need for any manual work at all.
Once the workflow is running on autopilot, next up is how to scrape data from a website into Excel and get it ready for use.
Exporting scraped data from Clay
Once your table is ready, exporting the data is effortless with Clay.
With just a few clicks, you can push data, including bulk verified email lists, to Excel or Google Sheets for further work. Similarly, with the right set-up, you can create an automated export to your CRM or outreach tool (Clay supports 150+ integrations that cover the entire B2B stack).
This is where most scrapers fail because while they give you raw data, it’s nowhere near ready for use in your business activities. Clay, on the other hand, bridges that gap by offering trigger automations that export your data into actionable workflows, for example:
- Send fresh data to your outreach tool for AI-powered email personalization.
- Push enriched leads straight to Salesforce or HubSpot for centralized customer profiles.
- Trigger Slack alerts to sales reps when a new target matches your ICP.
- Send cleaned Clay lists to PhantomBuster automation for LinkedIn/web actions, so scraping runs hit only verified targets.
If you’re wondering how to extract data from a website to Excel automatically, the flow is simple: run your Clay recipe, review the table, export to CSV/XLSX with a click, then simply upload that file to Excel (or Google Sheets) to do your filtering, sorting, and sharing.
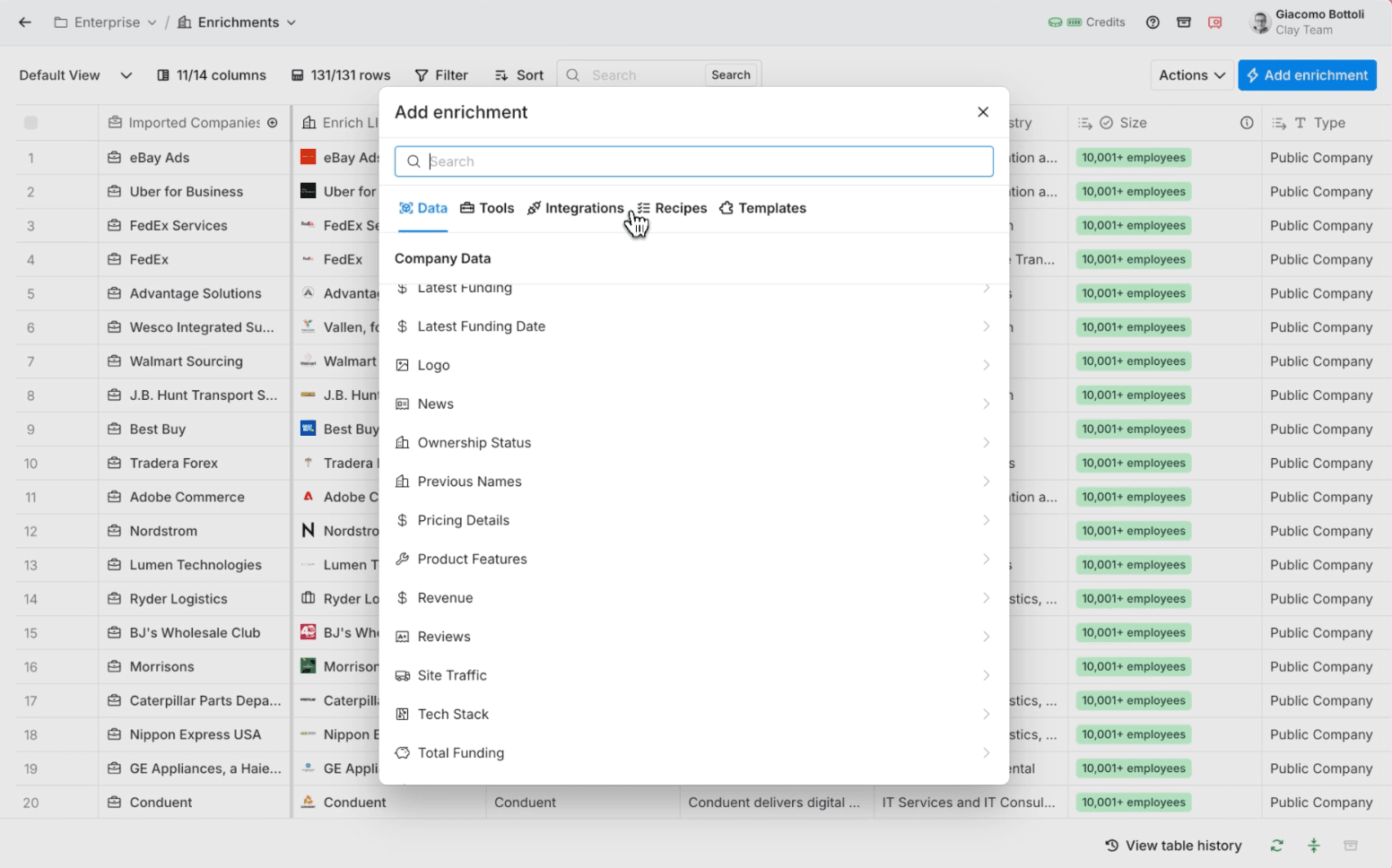
Before exporting, don’t forget to level up your lists with enrichment — this is where Clay really shines.
You can add tons of additional context like firmographics (size, industry, location), tech stack, funding rounds, social links, and intent-style signals (active hiring for key roles, new product pages, recent announcements):
Source: Clay
This way, by the time you’re ready to export from Clay, the enrichment layer, including verified contact information, has turned a plain data list into sales intelligence your team can actually act on. Before you export, use our free email finder to add the best contact details to your list.
Free Email Finder
Find verified email addresses instantly. Use it right here, completely free.
Your target's information
Fields marked with * are required
Enter just the domain (e.g., company.com) or paste a website URL
Please enter a professional email address
Please fill in all required fields
For more detailed info on how to scrape website data into Excel, check out Clay’s guide.
Common challenges of web scraping and how to avoid them
Even with the right strategy in place, web scraping can eventually hit certain roadblocks. Below are the most common challenges and how to deal with them:
Problem
What it means
Solution + how Clay helps
CAPTCHAs & IP blocking
Most sites will flag too many identical requests, then either throw a CAPTCHA or block your IP altogether.
Slow down your request rate, randomize timing, or use a trusted proxy. Clay automatically manages the request speed and balances workloads.
Dynamic pages
Data often doesn’t load all at once, it appears only after scrolling or clicking, making it easy to miss.
Clay’s dynamic rendering engine captures everything that appears on the page (even lazy-loaded content).
Honeypot traps
A decoy system that uses hidden elements or links to lure scrapers into revealing automation patterns, usually to flag or block them.
Clay filters out hidden traps and only pulls verified, visible data to keep your scrapes clean and accurate.
Messy or inconsistent data
You extract the right data, but rows are formatted differently (“1k” vs “1,000”), causing pure chaos in Excel.
Clay’s built-in transformation features standardize formats, or you can layer enrichment to auto-correct missing or inconsistent fields.
Legal & ethical boundaries
Some sites restrict scraping in their Terms of Service or robots.txt, ignoring which can cause serious issues.
Always stick to public, business-intent data and respect site limits. Clay automatically throttles requests and keeps scrapes within safe, compliant ranges.
As you can see, Clay web scraping is designed to take care of all these challenges in the background, giving teams full, verified, and compliant data without the headaches.
Extracting valuable data from the web is just the first step. Creating an automation engine that leverages that data for your sales and lead generation efforts is where it gets very complicated, which is why many companies turn to specialized experts like ColdIQ.
How can ColdIQ help with data scraping and outbound sales?
ColdIQ is an outbound growth agency that builds entire lead generation systems for B2B companies, from data scraping and enrichment to messaging, sequencing, and booked meetings.

Clay sits at the core of that system.
We use it to scrape data from multiple sources, organize it, and enrich every prospect or company profile with extra context like intent signals that track important changes.
Here’s how that works in practice:
- We design custom Clay recipes tailored to each client’s target market or ICP.
- We connect Clay with CRMs, outreach platforms, and other software.
- We continuously maintain and troubleshoot scraper automations.
- We add Claygent automations to surface sales-related insights like hiring signals, funding rounds, or decision-maker titles.
Once ready, we feed that data into our clients’ custom workflows, where outreach tools automatically pick it up to personalize emails and LinkedIn messages with context-aware info.
For most companies, trying to set up this entire system internally can get quite overwhelming and costly, forcing teams to focus on software, integrations, and constant monitoring.
ColdIQ completely removes that barrier by handling the entire lead generation process, from researching and extracting web data to setting up the email infrastructure and launching outreach, so your team gets a steady flow of qualified leads, and can focus purely on strategy and sales.
In short → Clay gives you the engine, ColdIQ keeps it running.
Getting started with automated web scraping
Finding the right business data can be complicated, but with the Clay scraping tool, it becomes a simple, automated workflow
Start small. Pick one site, install Clay’s Chrome extension, and test it out. Simply highlight what you need, map the fields, hit run, and within minutes, you’ll see clean data sitting neatly inside your Clay table.
Then start building on it — add enrichment columns, set it to update automatically, plug it into your CRM or outreach stack, and watch how quickly it starts feeding your pipeline.
For those who want a more detailed walkthrough before starting, check out Clay University — they’ll walk you through everything with interactive video lessons and guides.
And if you’d rather have an expert team handle the entire setup and execution, that’s where ColdIQ comes in.
We design and manage automated outbound systems built on Clay, covering data collection, enrichment, and outreach, delivering a consistent flow of qualified leads for your business.


